Problem
Navigating through the many service offerings within the Databricks platform can be challenging. With its various workspaces including Machine Learning, Data Science, SQL Analytics, and Data Engineering, Databricks is truly a unified platform which offers services to support all stakeholders within the data and advanced analytics domain. However, customers are interested in learning more about the various storage, compute, and workspace features that are available in Databricks
Solution
In this article, you will learn about the various components of workspaces, compute, and storage in Databricks. As Data Engineers, Citizen Data Integrators, and various other Databricks enthusiasts begin to understand the various benefits of Spark as a valuable and scalable compute resource to work with data at scale, they would need to know how to work with this data that is stored in their Azure Data Lake Storage Gen2 (ADLS gen2) containers. Azure Databricks offers the capability of mounting a Data Lake storage account to easily read and write data in your lake. You will also learn more about the various compute modes which serve different use cases. These include Apache Spark, Photon, and SQL Serverless Endpoints in Databricks. Finally you will learn about the Data Science and Engineering, Machine Learning, and SQL workspaces in Databricks along with their capabilities.
Storage
Databricks File System (DBFS) is available on Databricks clusters and is a distributed file system mounted to a Databricks workspace. DBFS is an abstraction over scalable object storage which allows users to mount and interact with files stored in ADLS gen2 in delta, parquet, json and a variety of other structured and unstructured data formats. Developers can store files in a FileStore which is a folder in DBFS where you can save files and have them accessible to your web browser. There are a variety of Databricks datasets that come mounted with DBFS and can be accessed through the following Python code: display(dbutils.fs.ls('/databricks-datasets')). DBFS, Spark and Local file APIs can be used to read and write to DBFS file paths. Databricks also supports Apache Hive which is a data warehouse system for Apache Hadoop that provides SQL querying capabilities for data in HDFS. Hive supports structure on unstructured data. A variety of Apache Spark tables are supported including Managed and External tables. DBFS can be accessed through the UI or mountpoints
Compute
Notebooks and jobs within Databricks are run on a set of compute resources called clusters. All-purpose clusters are created using the UI, CLI, or REST API and can be manually started, shared, and terminated. The second type of cluster is called a job cluster which is created, started, and terminated by a job. The following workloads utilize these all-purpose and job clusters.
- Data engineering workloads are automated and will run on job clusters created by schedulers.
- Data analytics workloads are interactive and will run Databricks notebook commands on all-purpose clusters.
The available cluster modes include High Concurrency (Optimized for concurrent workloads and supports SQL, Python, and R workloads), Standard (Optimized for single-user clusters and supports SQL, Python, R, and Scala workloads), and Single Node (contains no workers and is ideal for single user clusters that need to compute low data volumes). As for runtime versions, they include the core components that run on Databricks there are a few available options which include the following:
- Databricks Runtime includes Apache Spark and other components that enhance of big data analytics and workloads.
- Databricks Runtime for Machine Learning includes machine learning and data science libraries such as TensorFlow, Keras, PyTorch, and XGBoost.
- Databricks Runtime for Genomics includes components for working with genomic and biomedical data.
- Databricks Light includes Apache Spark and can be used to run JAR, Python, or spark-submit jobs but is not recommended for interactive of notebook job workloads.
Many of these runtimes include Apache Spark, which is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters. There have been recent advancements towards a newer engine called Photon which is a vectorized engine developed in C++ and is intended to improve Spark and SQL query performance.
Databricks offers auto-pilot options for auto-scaling between a minimum and maximum number of nodes, along with the capability of terminating the cluster after a period of inactivity to prevent incurring unnecessary costs. Cluster nodes have a single driver node which runs the main function and executes parallel operations on the worker nodes which read and write data. The min and max worker specification setting allows you to set the autoscaling range. There are quite a few options for worker and driver types and Databricks recommends Delta Cache Accelerated worker types which creates local copies of files for faster reads and supports delta, parquet, DBFS, HDFS, blob, and ADLSgen2 format files.
Other available features of clusters include Spot instances for cost savings which use warm instance pools to reduce times for Databricks cluster start and auto-scaling. Finally, with ADLS credential passthrough enabled, the user’s Active Directory credentials will be passed to Spark to give them access to data in ADLS. The figure below shows the details required to create a cluster from the Databricks UI.
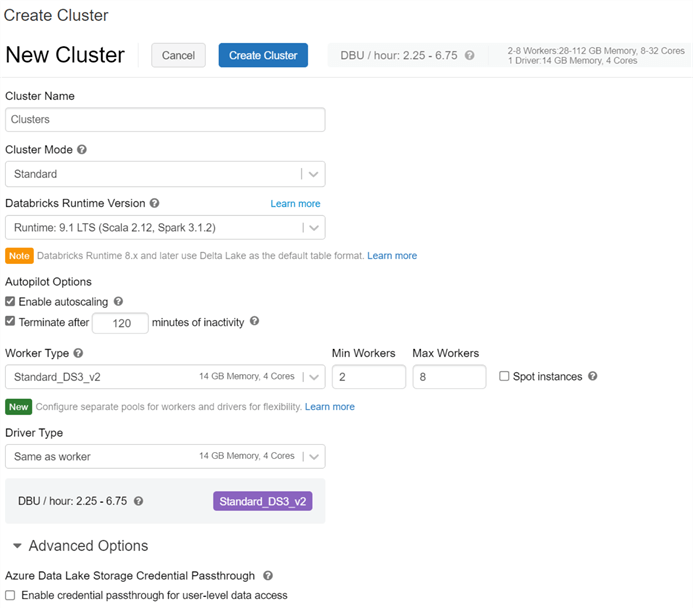
In addition to clusters, pools within Databricks are a set of idle instances that can reduce cluster start up and auto scaling times by attaching clusters and allocating worker and driver nodes from the pool. The figure below shows the configurations required within the ‘Create Pool’ UI.

Databricks also offers serverless compute capabilities for its SQL workspace. Serverless SQL operates on a pool of servers which fully managed by Databricks and runs on Kubernetes containers and can be quickly assigned to users and can be scaled up during heavy load times. Another benefit of Serverless SQL is that users will not need to wait for clusters to start up or scale out since compute will be instantly available. With Serverless SQL, users can easily connect to the endpoints with BI tools such as Power BI using built in JDBC/ODBC driver-based connectors. The figure below shows the UI for creating and configuring Serverless SQL endpoints.
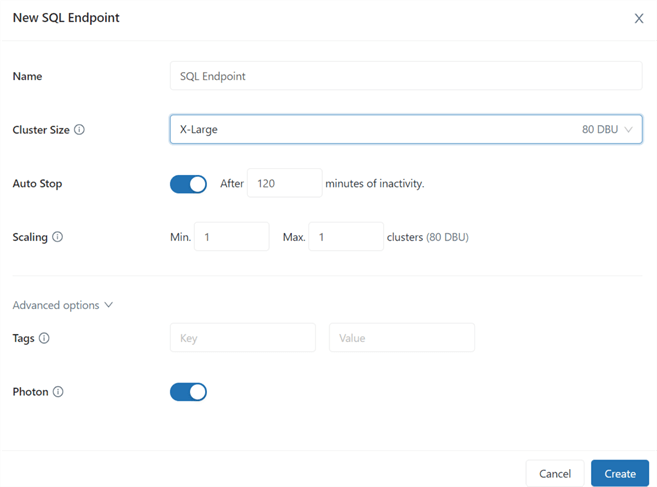
Workspaces
Within Databricks, there are a few different workspaces which are designed for different personas including Data Science, Data Engineering, Machine Learning, SQL, and Business Analysts. Workspaces are environments for accessing your Databricks services which include notebooks, libraries, dashboards, experiments, and more. In this section, we will explore these various workspaces along with the features that they offer.
Data Science and Engineering
The Data Science and Engineering workspace, shown in the figure below, is the most common workspace used by Data Engineering and Data Science professionals. Within this workspace, you will be able to create notebooks for writing code in either Python, Scala, SQL, or R languages. Notebooks can be shared, secured with visibility and access control policies, organized in hierarchical folder structures, and attached to a variety of high-powered compute clusters. These compute clusters can be attached at either the workspace or notebook level. It is within these notebooks where you will also be able to render your code execution results in either tabular, chart, or graph format.

Once you have completed your code development in your notebook, you will also have the option of adding it to Repos, shown in the figure below, which provides integration with remote Git repository providers. With Repos, you will be able to clone remote repos, manage branches, push and pull changes, and visually compare differences on commit.

The Databricks Workspace also offers Library UI, shown in the figure below, which provides you with the option of having either third party (e.g.: PyPI, Maven, CRAN) or custom code (e.g.: .whl, .egg, JAR) available for notebooks and jobs within the workspace that run on clusters. These libraries can be written in Python, Java, Scala, and R languages.
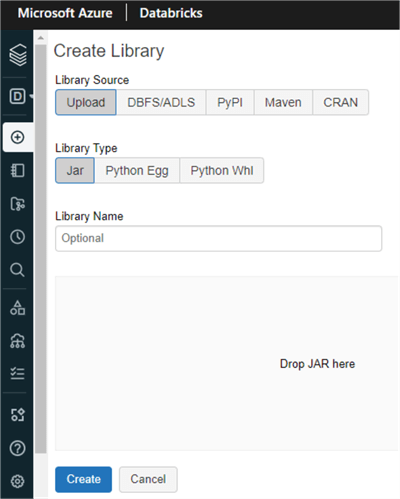
In a scenario where you would be interested in running your notebook code which may contain ELT and other data engineering scripts on a recurring basis, you could create and schedule a job from your notebook. The Job Scheduler UI, shown in the figure below, is where you would need to specify whether this is a manual or scheduled job along with the date and time intervals. The compute must be specified and you could also add status email alerts and parameters as needed.

Data within the workspace can be accessed via the Databricks File System (DBFS) which is mounted to the workspace with direct access to ADLS gen2. Hive tables can also be created programmatically in the notebook of with the out of box Create Table UI, shown in the figure below which allows you to create tables and import data.

Your workspace also comes equipped with Partner Connect, shown in the figure below, which allows you to easily integrate your Databricks SQL endpoints and Databricks clusters with a variety of other data ingestion, transformation, visualization, and advanced analytics tools.

The Data Science and Engineering workspace also supports the capability of creating MLflow Experiments, shown in the figure below, which let you organize and control access to MLflow runs for an experiment. There are robust features available within MLflow Experiments for visualizing, searching for, comparing runs, and downloading run artifacts.

Finally, within the workspace, you will also have access to a variety of user, group, and workspace administrator settings within the Admin Console, shown in the figure below. You’ll be able to control fine grained permissions around admin privileges, workspace access, SQL access, cluster creation at a user level. Groups can also be created with members that have certain entitlements. Finally, Workspace Settings within the Admin Console allow you to define access control, storage, job, cluster, and advanced level settings.

Machine Learning
The Machine Learning workspace, shown in the figure below, is similar to the Data Science and Engineering workspace in that it offers many of the same components. In addition, this Machine Learning workspace offers added components for Experiments, Feature Stores, and ML Models. This workspace supports an end-to-end machine learning environments including robust components for managing feature development, model training, model serving, and experiment tracking. Models can be trained manually or through AutoML. They can be tracked with MLFlow tracking and support the creation of feature tables for model training and inferencing. Models can then be stored, shared and served in the Model Registry.

The figure below shows the Feature Store UI within the Machine Learning workspace, which is a centralized repository of discovery and sharing of features which can be used for model training and inference.

The Registered Models UI, shown in the figure below, provides a Model Registry for managing the lifecycle of MLFlow Models. It provides model versioning, stage promotion details, model lineage, and supports email notifications.

SQL
As customers and organizations continue adopting the Lakehouse paradigm, it is critical for them to have similar capabilities of their traditional Data and BI systems when applying business intelligence and SQL based analysis on their Lakehouse data. With pioneering Lakehouse architectures, there has been a need to persist aggregated and dimensional data within SQL server-based systems in addition to the lake. This parallel effort to persist data in both the lake and a SQL database has been adopted in order to address the challenges associated with easily querying, visualizing, and analyzing dimensional data with traditional SQL and BI tools such as SSMS and Power BI.
Since there are inefficiencies and cost implications with persisting data in multiple systems, leading cloud providers now provide a variety of tools to support the seamless integration of BI and SQL analysis on Lakehouse data with experiences much like the traditional BI and Data tools on the market. Microsoft’s Synapse Analytics offers this capability through its SQL endpoints which provides users the ability to query, analyze, and perform BI on their Lakehouse data using traditional tools including SSMS and Power BI. Databricks introduced SQL Analytics to address some of these Lakehouse Paradigm challenges. Customers are interested in learning more about Databricks’ SQL Analytics.
The Databricks SQL workspace, shown in the figure below provides a native SQL interface and query editor, integrates well with existing BI tools, supports the querying of data in Delta Lake using SQL queries, and offers the ability to create and share visualizations. With SQL Analytics, administrators can granularly access and gain insights into how data in being accessed within the Lakehouse through usage and phases of the query’s execution process. With its tightly coupled Integration with Delta Lake, SQL Analytics offers reliable governance of data for audit and compliance needs. Users will have the ability to easily create visualizations in the form of dashboards, and will not have to worry about creating and managing complex Apache Spark based compute clusters with SQL serverless endpoints.

The figure below shows the SQL Queries UI along with how easy it is to query your Lakehouse data either in the Databricks DBFS or ADLS gen2 account by writing simple SQL statements. Notice also that with this SSMS like UI experience, you can easily see your schemas and tables to the left, can write your SQL query easily with live auto complete, and view the query results, and stats in a single UI.

Additionally, by writing SQL code similar to the following script, you could also create tables using parquet files stored within your ADLSgen2 account.
CREATE TABLE nyc_taxi.yellowcab USING parquet LOCATION '/data/nyc_taxi/parquet/yellowcab.parquet
The figure below shows the SQL Dashboard UI. Custom Dashboards can be easily created, pinned and visualized within the UI. Additionally, there are various sample dashboards that are available in the gallery.

The figure below shows the Query History UI which is an easy-to-use UI that offers a SQL DBA type of experience for viewing history and additional pertinent statistics of how SQL Queries performed using SQL endpoints. From a SQL DBA stand point, this can be used for monitoring, management, debugging, and performance optimization.

Next Steps
- Understand how to Mount an Azure Data Lake Storage Gen2 Account in Databricks (mssqltips.com)
- Read more about Designing an Azure Data Lake Store Gen2 (mssqltips.com)
- Read more about Data Science & Engineering workspace – Azure Databricks | Microsoft Docs
- Read more about Databricks workload types: feature comparison | Databricks
- Read more about Databricks SQL documentation | Microsoft Docs
- Read more about Databricks Machine Learning documentation | Microsoft Docs

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


