By: John Miner | Comments (2) | Related: > Azure
Problem
Many companies are building a Modern Data Platform (MDP) so that various organizational groups can have access to the information stored in one central place in the cloud. Azure Data Lake storage is an ideal place to store and/or stage data before ingestion into an Azure SQL Data Mart. Processing the information stored in Azure Data Lake Storage (ADLS) in a timely and cost-effective manner is an import goal of most companies. How can we update the Azure SQL Data Mart in an automated way?
Solution
PowerShell is a scripting language that can be used to automate business processing. Most modern Microsoft Windows Operating Systems have the language pre-installed as a default. Today, we are going to learn how to create an Extract, Transform and Load (ETL) script to update the data mart with the most recent file(s) stored in the data lake.
Business Problem
Our boss has asked us to continue with the Modern Data Platform (MDP) proof of concept (POC) for the World Wide Importers Company. Currently, we have an enriched (de-normalized) customer data file stored in the Azure data lake. We have been asked to create a process which will update the customer table with the latest information.
Architectural Diagrams
Complex ideas can sometimes be expressed more effectively using a diagram. That is why component and data flow diagrams are essential for any large complex project.
I have already gone over all of the concepts used in this design in prior tips. See table below for future research.
| No | Topic | Link |
|---|---|---|
| 1 | Managing an Azure Data Lake Storage. | Article #1 |
| 2 | Deploying an Azure SQL Database. | Article #2 |
| 3 | Using Windows Task Scheduler. | Article #3 |
| 4 | Working with directories and files. | Article #4 |
| 5 | Processing text files with PowerShell. | Article #5 |
| 6 | Creating a custom PowerShell ETL script. | Article #6 |
The image below is the component diagram for this proof of concept. We are going to leverage a virtual machine to supply both the computational processing power and scheduling software for the project.
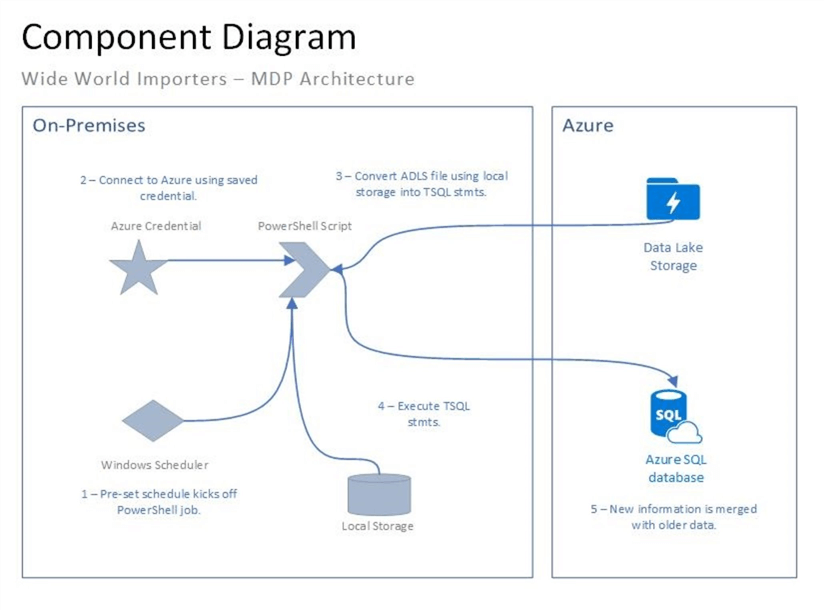
Let’s review how this process is going to work. At a prescheduled time, the Windows Task Scheduler will execute our customer ETL script written in PowerShell. The PowerShell script will connect to Azure using a credential saved beforehand in a JSON file. Both Azure Data Lake Storage and Azure Blob Storage do not support read from file commands. Therefore, we can only import or export files. The local temp directory will be used to save a copy of the enriched customer data file.
Now that we have the data file, we need to insert the data into a staging table in the data mart. One way to do this task is row by agonizing row (RBAR). While this technique is not optimal, it works for small to medium size data files. Last but not least, a couple of helper stored procedures can be used to truncate the staging table at the right time and merge the staging table data into the mart table data.
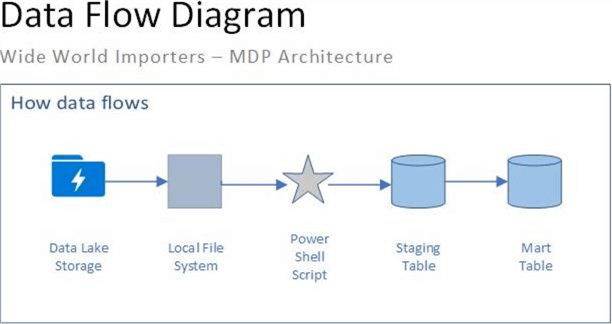
The data flow diagram below depicts how information will flow between the components in our system design. The customer data file is exported to the local file system. The PowerShell script moves the information into the staging table. Last but not least, stored procedures merge the staging table data with the mart table data.
Pseudo Code
Creating Pseudo Code and/or gathering functional design requirements before coding a program ensures that my ideas are coherent, can be shared with others, and can be reviewed for logical errors. The table below shows each step that I want to implement in my PowerShell ETL script.
| Step | Description |
|---|---|
| 1 – Connect to Azure. | Use a credential to log into Azure. |
| 2 – Validate temp directory. | Create directory if it does not exist. |
| 3 – Export ADLS file to temp directory. | Save remote file to local folder. |
| 4 – Load TSV file into memory. | Read in file as string array. |
| 5 – Clear staging table. | Truncate the staging table. |
| 6 – For each element of the array. | Data processing. |
| A – Parse string into columns. | Divide the string into logical columns. |
| B – Transform into TSQL. | Create insert statement for each record. |
| C – Execute TSQL statement. | Insert data into staging table. |
| 7 – Merge staging with mart table. | Perform the required insert, update or delete commands. |
Since we have a solid plan on how to accomplish our business tasks, it is now time to start coding. We will use a combination of system and user defined cmdlets. A cmdlet (pronounced "command-let") is a lightweight PowerShell script that performs a single function or task.
Azure Components
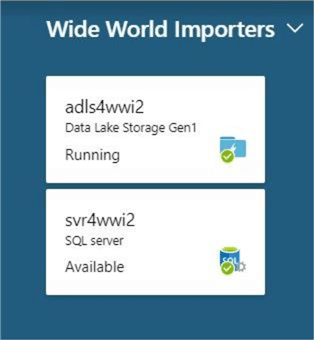
There are two main components being used in the Architectural Diagram. First, I am re-using the Data Lake Storage account named adls4wwi2. The credentials used by the PowerShell job should have both RBAC and ACL rights to the folders and files. Second, I deployed an Azure SQL server named svr4wwi2 and created a Azure SQL database named dbs4wwi2. The screen shot from the portal shows my two services pined to my dashboard.
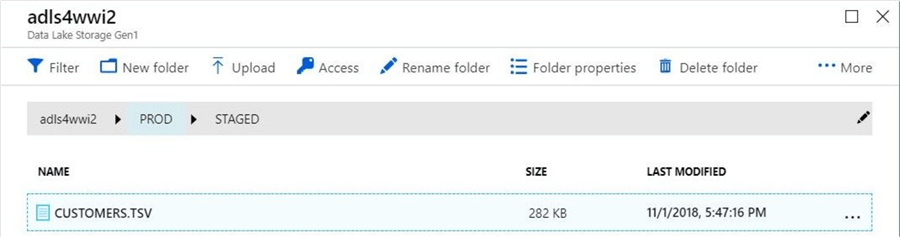
In my last article, a fully de-normalized customer data file was saved in tab delimited format and imported into the Azure Data Lake Storage account. The image below shows the full path to the file.
Azure SQL database supports three service tiers for a single database. The basic tier should be used only for a toy database since it has a 2 GB size limit. The standard tier database includes storage for 250 GB of data and the premium tier database includes storage for 500 GB of data. The high service levels of both the standard and premium tiers can reach a maximum database size of 1 TB and 4 TB respectively. Since these numbers do change, please see the pricing page for current specifications.
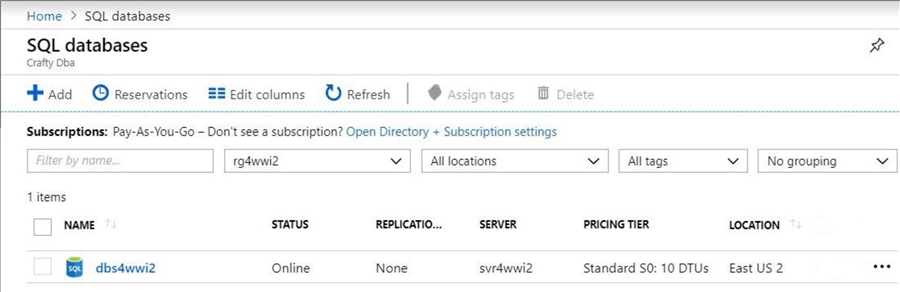
The above image shows our database tier set at the lowest standard level S0. If you are worried about space, please take a look at row and page compression. This might save you money if you are at the threshold of a service level. Of course, the will be a slight impact on CPU usage which will show up in your DTU total. For a listing of features supported by Azure SQL database, please take a look at this Microsoft web page.
We now have both of our Azure components deployed. Our next step is to create the database schema for our data mart.
Azure SQL Database
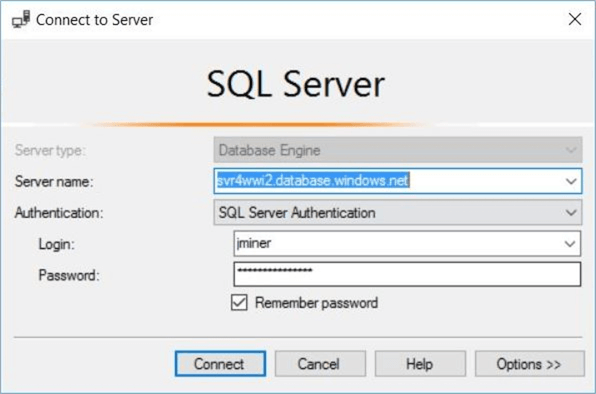
The first step in building our database schema is to log into the logical server using the latest version of SQL Server Management tools (SSMS). The image below shows the jminer standard security user logging into the svr2wwi2 logical server.
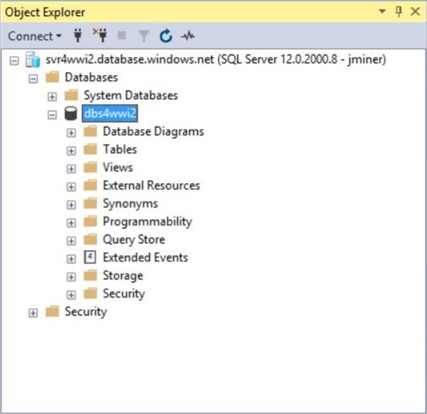
The Azure SQL Server database named dbs4wwi2 has been already deployed from the Azure portal. Right now, it is an empty database without any objects. The image below shows the object explorer in SSMS.
There are four objects that make up our database schema for this project. The Customer_Data table has an instance in both the Stage and Mart schemas. The Truncate_Customer_Data stored procedure is used to clear out the staging table. The key component of the design is the Merger_Customer_Data stored procedure which keeps the Mart table in sync with the Stage table.
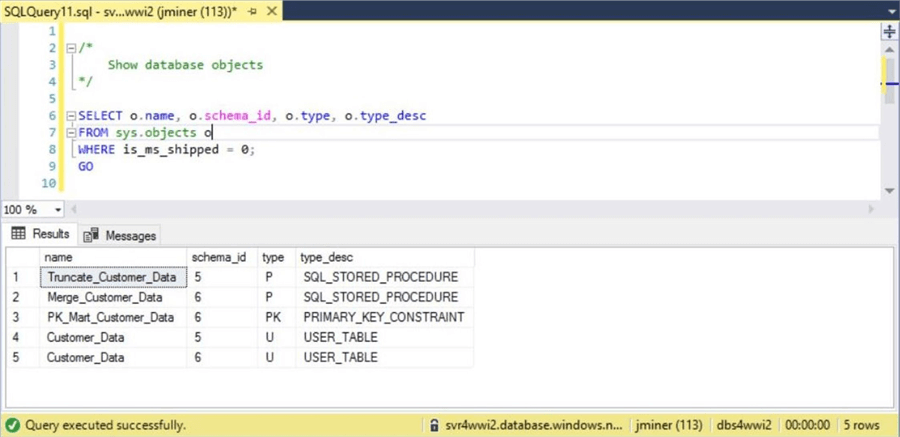
The above image shows the objects that make up our database schema. Please use the enclosed script to build your own version of this database.
The Transaction SQL MERGE statement will be used to synchronize the staging table with the mart table. In data modeling terms, we will be using a TYPE 1 slowly changing dimension. In short, the existing data will be over written with the new data.
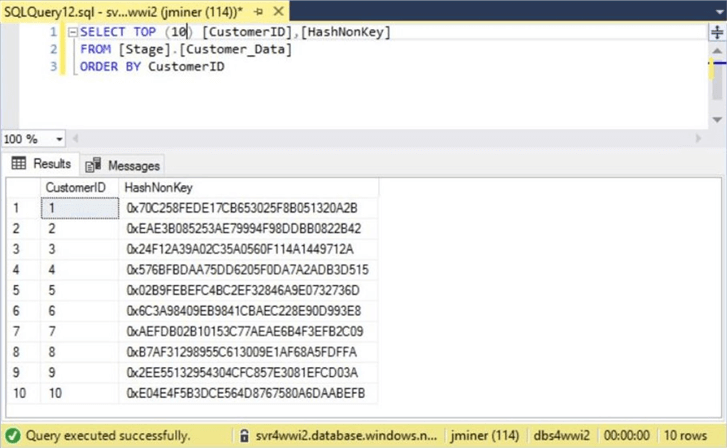
The above table shows the staging table with a computed column named HashNonKey. Why is this column added to the table?
The MERGE statement compares records in the target table (mart) with the source table (staging) when the tables are joined on a primary key. If the record exists in the mart table but not in the staging table, we want to DELETE the mart record. If the record exists in the staging table but not in the mart table, we want to INSERT the staging record. If the record exists in both tables, do we always UPDATE the mart record regardless of the fact that the records might be equal?
We could create a complex expression in which we compare every single field in the mart table with the stage table. If any fields are different, we can update the record. However, crafting this custom code can be time consuming. A better solution is to create a hash value of all non-primary key fields in the staging table and save this value in the mart table. Now, regardless of the type and number of fields, we just compare two 16-byte binary numbers to look for a record change.
--
-- Using hash key to determine record change
--
[HashNonKey] AS (Convert([varbinary](16), HashBytes('MD5', Concat
(
[CustomerName],
...
[ValidTo]
)
The above T-SQL snippet shows a partial definition of the HashNonKey column. This same technique can be used to create a HashKey column if composite keys are heavily used in your design.
PowerShell Script
I am going to start writing and debugging sections of code that will be part of our final solution. To make the coding a little simpler, I am going to call the Write-To-Log custom cmdlet I designed in the last article. Instead, I will be writing out messages as console output using the Write-Output cmdlet.
Another design consideration that I want to plan for is the fact that a Virtual Machine takes up local data center resources. Our current data center is at capacity. Therefore, I want the program to work in an Azure Virtual Machine or Azure Automation.
#
# Name: Main
# Purpose: This is the main section of code.
#
# Location of program (automation or client)
$compute = "client";
# Messaging
Write-Output (" ");
Write-Output ("Start - Load ADLS Customer data into Azure SQLDB.");
# Set variables
$server = "svr4wwi2";
$database = "dbs4wwi2";
$store = "adls4wwi2";
The above PowerShell snippet declares a variable named $compute which can be used to conditionally execute code depending on the deployment target of the script. Also, the names of the Azure components are set for use later on.
Connect To Azure
The first step of our algorithm is to connect to the Azure subscription. This can be done by using an account that has access to the subscription and components. I am assuming that the credentials were manually saved to a local JSON file using the Save-AzureRmContext cmdlet. The Import-AzureRmContext cmdlet, which is an alias for the Connect-AzureRmAccount cmdlet, can be used to connect to Azure.
#
# Step 1
#
# local computer
if ($compute -eq "client")
{
# Import security credentials
Import-AzureRmContext -Path "C:\MSSQLTIPS\MINER2018\ARTICLE-2018-11-BATCH-AUTOMATION\AZURE-CREDS.JSON"
| Out-Null;
# Manual error handling
if ($Error.Count -ne 0) { Write-Error -Message $_.Exception -ErrorAction Stop; };
# Messaging
Write-Output ("Step 1 - Connect using saved credential.");
};
There are three more interesting pieces of code in this example. First, the Out-Null cmdlet can be used to hide any output that is generated in a pipeline command. Second, there are cases in with the try/catch clause of PowerShell does not capture an error. In those cases, we can use the global error collection stored in the $Error variable. Third, the Write-Error cmdlet can be used to display an error message and terminate the program with one call.
Now that we have a connection to Azure, we can download the data file from Azure Data Lake Storage (ADLS).
Temp Directory
Local storage will be used to save a copy of the CUSTOMERS.TSV file from Azure Data Lake Storage. Since this file is only needed on a temporary basis, we can save the file in the temp sub-directory.
The code below uses the Test-Path cmdlet to determine if the directory exists. If the directory does not exists, the New-Item cmdlet can be used to create the directory.
#
# Step 2
#
# Create temp directory
$path = "c:\temp";
If (!(test-path $path))
{
# Create a new directory
New-Item -ItemType Directory -Force -Path $path | Out-Null;
# Messaging
Write-Output ("Step 2 - Make temp directory.");
}
else
{
# Messaging
Write-Output ("Step 2 - Temp directory already exists");
};
In a nutshell, the above code snippet makes sure a c:\temp directory exists for our ETL process.
Export ADLS File
Azure Data Lake Storage is a service in which file can be imported or exported. We can’t directly read the bytes in the data file. Therefore, we need to save the data file into a temporary directory for processing.
The code snippet below transfers the data file from remote to local storage. The Export-AzureRmDataLakeStoreItem is the cmdlet that performs this task.
#
# Step 3
#
# Set variables
$srcfile = "/PROD/STAGED/CUSTOMERS.TSV";
$dstfile = "C:\\TEMP\\CUSTOMERS.TSV";
# Download the file
Export-AzureRmDataLakeStoreItem -AccountName $store -Path $srcfile -Destination $dstfile -Force | Out-Null;
# Manual error handling
if ($Error.Count -ne 0) { Write-Error -Message $_.Exception -ErrorAction Stop; };
# Messaging
Write-Output ("Step 3 - Grab Customer remote data file from ADLS.");
Load File Into Memory
The next step in the PowerShell script is to read the data file into memory as an array of strings. We can use the Get-Content cmdlet to perform this operation in one line of code. Just remember the size of the files does matter. For small to medium files, this technique will work file.
For larger files, I suggest using the System.IO.StreamReader class available from the .NET framework. This means you have to handle opening the file handle, process each line of the file and closing the file handle. I leave that technique for you to research.
#
# Step 4
#
# Read in file strings
$file = Get-Content -Delimiter "`n" $dstfile;
# Manual error handling
if ($Error.Count -ne 0) { Write-Error -Message $_.Exception -ErrorAction Stop; };
# Messaging
Write-Output ("Step 4 - Read in customer data file.");
The above code reads the contents of the customer data file into a variable named $file.
Clear Staging Table
The customer table in the stage scheme needs to be cleared of records before loading the latest data file. We already have a stored procedure designed to perform this task. The Exec-NonQuery-SqlDb custom cmdlet can be called with the correct parameters to perform this action.
When executing the script on a local computer, we have to hard code both the user name and password. In future articles, I will examine Azure services that can store this information for us.
#
# Step 5
#
# local computer
if ($compute -eq "client")
{
$User = "jminer";
$Password = "d4aFd6cfb19346Ca";
};
# Set connection string
$ConnStr = 'Server=tcp:' + $server + '.database.windows.net;Database=' + $database +
';Uid=' + $User + ';Pwd=' + $Password + ';'
# Make TSQL stmt
$SqlQry = "EXEC [Stage].[Truncate_Customer_Data];";
# Call stored procedure
$Count = Exec-NonQuery-SqlDb -ConnStr $ConnStr -SqlQry $SqlQry;
# Manual error handling
if ($Error.Count -ne 0) { Write-Error -Message $_.Exception -ErrorAction Stop; };
# Messaging
Write-Output ("Step 5 - Truncate customer staging table.");
To recap this section, we are going to leverage a custom cmdlet design in a prior article to execute a stored procedure that does not return any data.
Data Processing
The actual processing of the data file loaded into an array is the largest section of code in this program. However, the logical behind the code is quite simple. For every record excluding the header record, we want to parse the string data into a T-SQL INSERT statement. The actual T-SQL statement can be broken down into two parts: the front of the statement which is static and the back of the statement which contains the dynamic values to insert.
In the code below, find the comment for Section A. The table contains 29 distinct column names. Therefore, to reduce the code seen in this article, I did not include column names. However, it is good practice to include the names. If fact it is required in our case since, we have a calculated column at the end of the table.
There are three string functions in the .Net Framework that we leveraging to perform our work. The Split method is used to divide each line in the file into a column array. The Trim method removes the double quotes from the start and end of each column. The Replace method removes any unwanted single quotes from our string values. Single quotes will cause syntax errors when crafting a dynamic SQL statement.
The code snippet below shows the outline of step 6 in our program algorithm. There are two types of fields to format for the dynamic T-SQL statement. Numerical Data types do not need to be surrounded with single quotes in T-SQL. Other data types like dates and strings do need to be surround with single quotes. Last but not least, string columns with questionable data need to be scrubbed for single quotes.
In the code below, find the comment for Section B. This section has on example of each type of field that needs to be processed and formatted. See the final program at the end of the article for complete details.
#
# Step 6
#
# A - Front part of T-SQL statement
$front = "INSERT INTO [Stage].[Customer_Data] VALUES "
# make single insert statements
for ($i = 1; $i -lt $file.Count; $i++)
{
# grab a line of data & split into columns
$line = $file[$i];
$columns = $line.split([char]0x09);
# B - Back part of T-SQL statement = start = values string
$back = "";
$back += "(";
# Type 1 - {column = customer id, type = int}
$back += $columns[0].Trim([char]0x22) + ",";
# Type 2 - {column = customer name, type = string}
$back += "'" + $columns[1].Replace("'", "").Trim([char]0x22) + "',";
# Code removed to reduce snippet size
# end = values string
$back += ")";
# Make TSQL statement
$SqlQry = $front + $back;
# Call stored procedure
$Count = Exec-NonQuery-SqlDb -ConnStr $ConnStr -SqlQry $SqlQry;
# Manual error handling
if ($Error.Count -ne 0) { Write-Error -Message $_.Exception -ErrorAction Stop; };
}
# Messaging
Write-Output ("Step 6 - Insert data into customer staging table.");
Again, this PowerShell snippet creates and executes single INSERT statements. This type of processing will be slower than batching up the data using bulk copy. I will explore that technique in a future article.
Merging Tables
The data in the staging table needs to be merged with the data in the mart table. We already have a stored procedure designed to perform this task. The Exec-NonQuery-SqlDb custom cmdlet can be called with the correct parameters to perform this action.
The code below performs the task of merging the two tables in which newly found records are inserted, missing old records are deleted and changed records are updated.
#
# Step 7
#
# Make TSQL stmt
$SqlQry "EXEC [Mart].[Merge_Customer_Data];";
# Call stored procedure
$Count = Exec-NonQuery-SqlDb -ConnStr $ConnStr -SqlQry $SqlQry;
# Manual error handling
if ($Error.Count -ne 0) { Write-Error -Message $_.Exception -ErrorAction Stop; };
# Messaging
Write-Output ("Step 7 - Merge staging data into mart table.");
# Messaging
Write-Output ("Finish - Load ADLS Customer data into Azure SQLDB.");
Script Testing
The most important part of any development project is the positive and negative testing of the code. Make sure that the credentials that you saved locally have access to all required Azure components. The screen shot below was taken from the console window in the PowerShell Integrated Scripting Environment (ISE). We can see that each step of the script has executed successfully.

The whole point of the PowerShell ETL script was to update an Azure Data Mart with files from ADLS. If we go into SQL Server Management Studio and query the customer mart table, we can see that the enriched data is now in the system.
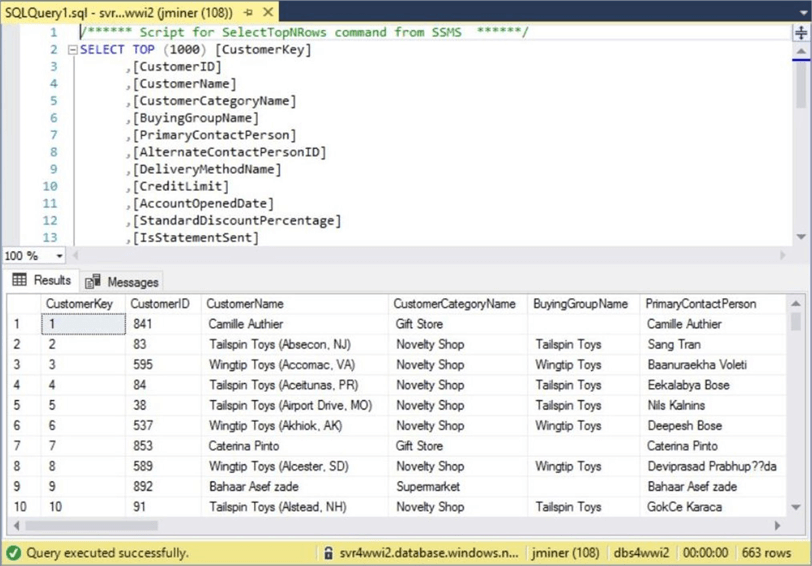
There were two goals of this project. One was to load the data in a timely manner. That is a subjective goal since a 5-minute ETL job for one business problem might be an acceptable amount of processing time. On the other hand, the same time limit might not be acceptable if the business users are expecting up to the minute real time data. Because this job runs quickly, I am declaring that the first goal has been achieved.
The second goal was to find the most cost-effective way to execute the PowerShell ETL script. We will research this problem in the next section.
Pricing Tool
The Azure pricing calculator can be used to figure out how much a component will cost on a monthly and yearly basis. Moving data out of Azure to on premise will cost an egress charge. These charges are very minimal. Given the fact that the data files are already in an Azure Data Lake, how can we move the processing to the cloud?
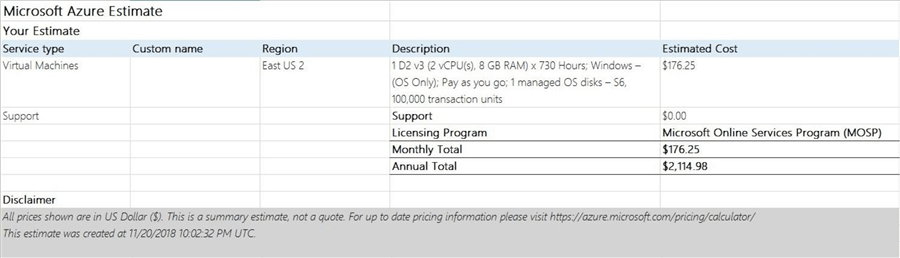
The first solution is to create a very simple virtual machine. We need a windows operating system installed with PowerShell and Task Scheduler. The below estimate without any discounts shows a yearly operating cost of $2115. Can we do better than that?
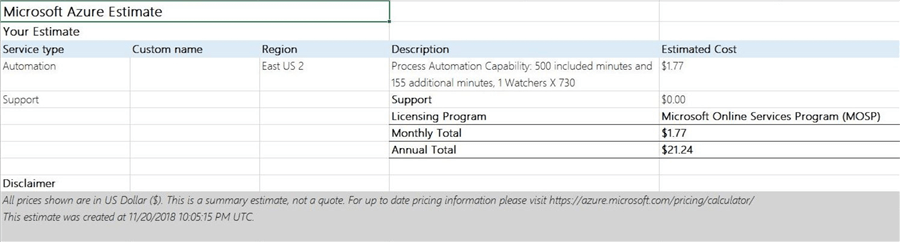
Azure Automation has been a cloud service for a very long time. This service has three types of Runbooks that can be scheduled to execute on a periodic basis.

I plug the numbers in for 500 minutes of process automation using the pricing calculator. As you can see below, we have a cost savings of almost $2000 per month. Unless you have 100 jobs to execute, it is cost effective to execute the jobs using this cloud service.
Summary
Today, I showed how to update an Azure Data Mart using data stored in Azure Data Lake storage. Processing the data in the cloud is the second step in creating a Modern Data Platform (MDP).
All of concepts that I covered during the creation of the ETL PowerShell script have been taught in prior tips. One step that I did leave out is the logging of successful steps to either a flat file or the windows event viewer. I did this to reduce the amount of code in the given examples. The enclosed complete script contains calls to the custom logging cmdlet. Here is a spoiler alert – the script is already set to be use with Azure Automation.
There are some parts of the program design that can be improved.
First, how can we store credentials such as a user name and password in a local encrypted file? Second, how can we process large files using a similar pattern? The Get-Content cmdlet is not the best choice for working with large data files and executing single INSERT statements is not the quickest way to load data into SQL Server. Third, the MERGE statement will fail with databases that have a small DTU footprint. This command really executes three distinct statements. Since batch size can’t controlled, one might have issues with TEMPDB and/or the LOG file growth when working with a large amount of records.
The two goals of this project were to process the information stored in Azure Data Lake Storage (ADLS) in a timely and cost-effective manner. Yes, there are limitations to the program that we developed today. However, this program will work with small to medium workloads in a relative short amount of time. Your mileage might vary. On the other hand, the cost comparison of infrastructure as a service (IAAS) – azure virtual machine and platform as a service (PAAS) – azure automation is night and day. For a small number of programs, azure automation is a very cost-effective solution.
I hope you enjoyed our exploration of PowerShell to create an ETL program. Stay tuned for more articles related to the Modern Data Platform (Warehouse).
Next Steps
- Implementing Azure Automation using PowerShell Runbooks
- Creating a service principle using PowerShell
- Importing raw data Into ADLS with PowerShell
- Converting raw data into enriched data with ADLA
- Using Azure Data Factory to orchestrate data processing






About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
