Problem
Nowadays, most organizations use websites to support their key business objectives and fulfill their users’ needs. Any web content is more or less worthless if it does not perform either of these two functions (Halvorson & Rach, 2012). Furthermore, organizations are evolving in relation to the new, rapidly changing business world, so should their web content. To diagnose problematic content, they need to examine web content periodically (Redsicker, 2012). The Python web scraping technique can extract relevant information from a web page. How can IT professionals use this technique to conduct a web content audit automatically?
Solution
To use web content to achieve business objectives and meet users’ needs, organizations must form content strategies that guide content creation, delivery, and governance (Halvorson & Rach, 2012). We often need to gather, audit, and analyze existing HTML content to practice content strategies. A web content audit sounds time-consuming for beginners. However, we can use audit tools to help. For example, we can use the web scraping technique in the Python programming language to capture basic information on a web page. To demonstrate using this audit tool, we create a fictitious project to conduct a web page content audit:
Edgewood Solutions maintains the SQL Server community website MSSQLTips.com, which was started in 2006. Talented IT professionals worldwide write articles to share their knowledge. Besides these technical articles, the website contains some administrative contents, for example, Copyright, Privacy, and Disclaimer. The CTO at Edgewood Solutions wants to audit this administrative content. For demonstration purposes, we focus on the Copyright page in this article.
Content strategy varies from organization to organization. So does the website content audit. Different content audit projects expect different outputs. Jankovic provides a list of information that we should gather from each piece of content on websites (Jankovic, 2020). Redsicker recommends a simple spreadsheet to include everything we discover in the content audit (Redsicker, 2012). Inspired by these authors' lists, we first design a spreadsheet that includes the following columns:
- Page Id: the identification number or code assigned to a web page.
- Page Title: the title HTML tag of a web page.
- Document Type: the purpose and objectives of a web page.
- URL: the internet address of a web page.
- High-frequency words: the words that appear most often on a web page.
- Meta Description: a tag in HTML, which summarizes a page’s content.
- Internal Links: hyperlinks that point to web pages on the same website.
- External Links: hyperlinks that point to web pages on other websites.
- Broken Links: hyperlinks that point to empty or non-existent web pages.
We then create a web scraper, a powerful tool for data gathering, to extract information from the HTML code. Many data science projects start with obtaining an appropriate data set. However, a well-structured data set is not always available. In that case, we should collect information from the web. The web scraping technique comes in handy. With the web scraping technique, we can automate gathering any information that we can access through web browsers. In practice, we can use Beautiful Soup, a Python library, to extract information from web pages.
The Python Beautiful Soup library provides many methods for accessing HTML elements. For example, we often use these two methods: “find()” and “find_all()” to discover desired data on a web page. When utilizing these two methods, 95% of the time, we use only the first two arguments: tag and attributes (Mitchell, 2018). This article delves into some advanced topics in HTML parsing. We explore how the Beautiful Soup library can work with other techniques to fulfill complicated tasks. These techniques are lambda expressions, regular expressions, Christian Kohlschütter's Boilerpipe library, and scikit-learn's CountVectorizer.
After retrieving text data from a web page, we explore some common steps to clean the text data. We also perform text analysis, including removing stop words, tokenizing the textual content, and counting word frequencies. The word frequencies help to know the topics of the web pages. In addition, the article uses the word cloud technique to visualize word frequencies. We then store all this information collected from the web page into a spreadsheet.
The author uses Microsoft Visual Studio 2019 to edit Python scripts and test these scripts using Python 3.10.0 (64-bit) on Windows 10 Pro 10.0 <X64>. To create an isolated environment for the project, the author adds a virtual environment using the following requirement.txt. As of this writing, this procedure cannot install the “wordcloud” library. we should download the “wordcloud-1.8.1-cp310-cp310-win_amd64.whl” file and then manually add the “wordcloud” library to the virtual environment using the pip command.
beautifulsoup4==4.10.0 boilerpy3==1.0.5 certifi==2021.10.8 charset-normalizer==2.0.9 cycler==0.11.0 fonttools==4.28.5 idna==3.3 joblib==1.1.0 kiwisolver==1.3.2 matplotlib==3.5.1 numpy==1.22.0 packaging==21.3 Pillow==9.0.0 pip==21.2.3 pyparsing==3.0.6 python-dateutil==2.8.2 requests==2.27.0 scikit-learn==1.0.2 scipy==1.7.3 setuptools==57.4.0 six==1.16.0 soupsieve==2.3.1 threadpoolctl==3.0.0 urllib3==1.26.7 wordcloud==1.8.1 xlwt==1.3.0
1 – Prerequisite
The focus of this article is on advanced HTML parsing. The goal is to introduce some advanced techniques. To walk through this article, we should be familiar with the basics of Python language, Regular Expressions, and the Beautiful Soup library. We should also know the steps to create a Python project and add a virtual environment using Microsoft Visual Studio. The following Python tutorials cover these topics:
- Learning Python in Visual Studio 2019
- Python Regular Expressions Explained with Examples
- Using Python to Download Data from an HTML Table to an SQL Server Database
Some familiarity with the top-down design approach would be helpful. This article explores the approach:
2 – Passing Lambda Expressions into the “find_all()” Method
Python lambda expressions (or lambda functions), defined by the keyword lambda, are anonymous functions. Lambda expressions are concise and usually have one line of code. Although we can spread an expression over several lines using parentheses or a multiline string, the expression remains a single expression. A lambda function can have zero or more arguments. The body of a lambda function is a return expression, which can be any expression. The syntax is as follows:
lambda <arguments> : <return expression>
For example, the following expression takes two arguments and returns the result of the calculation:
lambda x, y : x + 2*y + 3
The result of this expression is a function object; therefore, we can call this function as we call any other regular Python functions:
>>> lambda x, y : x + 2*y + 3 <function <lambda> at 0x00000279E20A5CF0> >>> (lambda x, y : x + 2*y + 3)(20,10) 43 >>>
After assigning a name to the lambda expression, we can call the function through the name with this Python code:
>>> test_function_2 = lambda x, y : x + 2*y + 3 >>> test_function_2(20,10) 43 >>>
The above lambda function is equivalent to writing this regular Python function:
>>> def test_function(x,y): ... return x + 2*y + 3 ... >>> test_function(20, 10) 43 >>>
We often use the Beautiful Soup "find_all(tagName, tagAttributes)" method to get a list of tags on the page. Furthermore, the "find_all()" method can also take a lambda expression as an argument. When we use a lambda expression in the "find_all()" method, the lambda expression should take a tag object as an argument and determine if the method should return the tag (Mitchell, 2018). That is to say, the return expression in the lambda body should return a Boolean.
Now, let us extract URLs on the landing page of the MSSQLTips.com site. The page contains different anchors shown in the following:
<a name="top"> <a href="#"> <a href="https://www.mssqltips.com/"> <a href="https://www.mssqltips.com/sql-server-webcast-signup/?id=891&src=HP" target="_blank" target="_blank"> <a href="/sqlservertip/7090/python-regex-examples/" target="_blank"> <a href="/author/nai-biao-zhou/"> <a href="/get-free-sql-server-tips/?ref=LeftGFSTSlant"> <a rel="noopener" href="https://www.linkedin.com/groups/2320891/" target="_blank">
Most times, the attribute “href” contains a valid URL. However, the attribute may contain an undesired value, for example, “#” or the original page URL. We can use a lambda expression to tell the “find_all()” method to return only desired tag objects. We use the following code block to access the landing page and find all anchor tags containing desired URLs.
import requests from bs4 import BeautifulSoup page_url = 'https://www.mssqltips.com/' response = requests.get(page_url) soup = BeautifulSoup(response.content, 'html.parser') links = soup.find_all(lambda tag: tag.name == 'a' and 'href' in tag.attrs and tag['href'] != '#' and tag['href'] != page_url) for link in links: print(link['href']) #Output sample #/get-free-sql-server-tips/?ref=JoinHeaderMenu #/sqlservertip/1948/sql-server/ #/tutorial/sql-server-101-tutorial-outline-and-overview/
3 – Using Regular Expressions in Web Scraping
Regular expressions allow us to find specific text patterns and extract desired data in web pages (Summet, 2014). Therefore, using regular expressions in web scraping projects can save us much development effort and headache. This section uses a two-step process to get the information we need. Firstly, we use regular expressions to match and extract all internal and external URLs on the landing page. Secondly, we extract subdirectories in internal URLs.
3.1 Passing a Regular Expression into the “find_all()” Method
We mentioned that the Beautiful Soup “find_all(tagName, tagAttributes)” method could get a list of tag objects on a web page. The function can take a regular expression argument as well for the data extraction.
The landing page of MSSQLTips.com contains internal links and external links. Rather than retrieving all links, we want to extract internal links only. We reviewed the URLs on the landing page. All the internal links either start with the base URL “https://www.mssqltips.com/” or start with a forward slash (/). We can use the following regular expression to represent the pattern.
^((https:\/\/)?www.mssqltips.com\/|\/).+
The "find_all()" method looks for anchor elements that have the "href" attributes, and the attributes match the preceding regular expression. The following Python script illustrates the syntax to use the regular expression in the "find_all()" method:
import re import requests from bs4 import BeautifulSoup page_url = 'https://www.mssqltips.com/' # Defines the regex to find all internal links regex = re.compile(r'^((https:\/\/)?www.mssqltips.com\/|\/).+') response = requests.get(page_url) soup = BeautifulSoup(response.content, 'html.parser') links = soup.find_all('a', {'href':regex}) for link in links: print(link['href']) #Output sample #/get-free-sql-server-tips/?ref=JoinHeaderMenu #/sqlservertip/1948/sql-server/ #/tutorial/sql-server-101-tutorial-outline-and-overview/ #/sqlservertip/6422/sql-server-concepts/
The CTO also want to check every external links in the landing page of the MSSQLTips.com. All external links should not contain the base URL of the MSSQLTips.com site. We can use the following regular expression to represent the pattern:
^(http:\/\/|https:\/\/|www\.)(?!(www\.)?mssqltips\.com).+
Then, we pass the regular expression to the “find_all()” method to find all external links on the landing page. The following Python script implements this idea:
import re import requests from bs4 import BeautifulSoup page_url = 'https://www.mssqltips.com/' # Defines the regex to find all external links regex = re.compile(r'^(http:\/\/|https:\/\/|www\.)(?!(www\.)?mssqltips\.com).+') response = requests.get(page_url) soup = BeautifulSoup(response.content, 'html.parser') links = soup.find_all('a', {'href':regex}) for link in links: print(link['href']) #Output sample #https://feeds.feedburner.com/MSSQLTips-LatestSqlServerTips #https://www.edgewoodsolutions.com
3.2 Using a Regular Expression to Extract Relevant Information
The landing page of the MSSQLTips.com site changes every weekday. The web application adds the newly published articles to the landing page and removes the previously published ones. Therefore, analyzing the full-path URLs on the landing page may not be meaningful. Instead, we want to collect a list of subdirectories from the landing page. A subdirectory (also known as a subfolder) helps people understand which directory of a web page they are on (Chi, 2021). For example, rather than recording the URL: https://www.mssqltips.com/sqlservertip/7090/python-regex-examples/, we only need to know that the lading page contains internal links to the "sqlservertip" subdirectory.
We can use a regular expression to extract subdirectories from internal links. For example, the following Python script presents the regular expression definition and then uses the expression to extract relevant information from the URLs.
# Define an empty set to stored unique subdirectories subdirectories = set() # The links variable represents a bs record set that contains internal links for link in links: # Defines the regex to match subdirectory in an URL regex2 = re.compile(r"^(?:https:\/\/www.mssqltips.com\/|\/)(?P<subdirectory>(\w+-?)*)\/") match_obj = re.search(regex2, link['href']) if match_obj: subdirectory = match_obj.group('subdirectory') subdirectories.add(subdirectory) for subdirectory in sorted(subdirectories): print(subdirectory) #Output sample #about #advertise #contribute #copyright #disclaimer
4 – Using BoilerPy3 Library to Extract Text from a Web Page
This content audit project asks us to count word frequencies, which helps us understand the page content. We first should extract text from the web page. As most web pages do, the "Copyright" page contains navigational elements and templates. We often find that web pages also contain advertisements. This boilerplate text, typically unrelated to the main content, can deteriorate our text analysis, so we should remove them (Kohlschütter et al., 2010). Christian Kohlschütter wrote a Java library, Boilerpipe, to detect and remove the surplus "clutter" (i.e., boilerplate, templates) around the main textual content of a web page.
Riebold created a package, "BoilerPy3," allowing us to use Christian's library in Python. To use functions in the package, we first create an extractor instance representing an extraction strategy. We then use the "get_content()" methods to extract the filtered text. For example, the following script creates an "ArticleExtractor" instance, which is tuned towards news articles. This extraction strategy works very well for most types of article-like HTML documents (Riebold, 2021).
from boilerpy3 import extractors page_url = 'https://www.mssqltips.com/copyright/' extractor = extractors.ArticleExtractor() response = requests.get(page_url) content = extractor.get_content(response.text) print(content) #Output sample #Search #Copyright #The entire web site may not be reproduced in any form without written permission #from Edgewood #Solutions . Some individual articles are copyrighted by their respective authors #and other content that has been used is referenced back to its original source on #the internet.
Besides the "ArticleExtractor," the "BoilerPy3" package provides other extractors that implement different extraction strategies. According to the project description on the web page "https://pypi.org/project/boilerpy3/,” several extractors, shown in Table 1, are available. Therefore, we can conduct some tests to check the accuracy of each strategy. This article uses the "ArticleExtractor" to extract text from the Copyright page on MSSQLTips.com.
| Strategy | Description |
|---|---|
| DefaultExtractor | A quite generic full-text extractor. |
| ArticleExtractor | A full-text extractor that is tuned towards news articles. In this scenario, it achieves higher accuracy than DefaultExtractor. This extractor works very well for most types of article-like HTML documents. |
| ArticleSentencesExtractor | A full-text extractor that is tuned towards extracting sentences from news articles. |
| LargestContentExtractor | A full-text extractor that extracts the largest text component of a page. For news articles, it may perform better than the DefaultExtractor but usually worse than ArticleExtractor. |
| KeepEverythingExtractor | Dummy extractor that treats everything as content. We use this extractor to track down SAX parsing errors. |
| NumWordsRulesExtractor | A quite generic full-text extractor solely based upon the number of words per block (the current, the previous, and the next block). |
Table 1 The Extraction Strategies (Riebold, 2021)
5 – Data Cleansing
The content audit project wants to report the high-frequency words on the Copyright page. However, the data on web pages is often unstructured; therefore, we need to clean the extracted data before further analysis (Gupta, 2019). In practice, we usually need to deal with numerical and text data. The steps to clean numerical data often involves removing duplicates, handling missing values, and dealing with outliers. By contrast, text data cleaning uses different techniques. Here are some common steps, also known as text pre-processing techniques (Imasogie, 2019):
- Make text all lower case
- Remove punctuation
- Remove numerical values
- Remove common, non-sensical text
- Tokenize text
- Remove stop words
Since we will use Scikit-learn’s CountVectorizer to remove stop words and convert text to a token count vector in the next section, this section implements the first four steps. We use the following Python user-defined function to perform these steps, shown in the following code block.
# Reference: https://medium.com/nwamaka-imasogie/stand-up-comedy-and-nlp-c7d64002520c def clean_text_data(raw_text:str) -> str: rtn_value = raw_text #1. Make text all lower case rtn_value = rtn_value.lower() #2. Remove punctuation rtn_value = re.sub(r'[{}©]'.format(re.escape(string.punctuation)), '', rtn_value) #3. Remove numerical values rtn_value = re.sub(r'\w*\d+\w*', '', rtn_value) #4. Remove common non-sensical text rtn_value = re.sub(r' *\n *', ' ', rtn_value) return rtn_value
6 – Using CountVectorizer in Python to Count Word Frequencies
The scikit-learn library provides a great tool, CountVectorizer, which converts a given text to numerical data so that a machine can understand (Jain, 2021). For example, the tool can transform the text into a vector according to each word's frequency. However, the tool can perform different levels of tokenization. Because we want to count word frequency, this project uses word-level tokenization. We also use a built-in stop word list to remove less informative words, for example, "in," "any," and "are." The following user-defined function take a string as an argument and return a dictionary that contain work frequencies.
from sklearn.feature_extraction import text from sklearn.feature_extraction.text import CountVectorizer # Uses CountVectorizer in Python to count word frequencies def count_word_frequencies(clean_text:str) -> dict: ''' Takes a clean string as an argument. Returns a dictionary that contains word frequencies. ''' custom_stop_words = ['site','web','llc','does','wwwmssqltipscom'] # Combine the custom stop words into the built-in stop words mssqltips_stop_words = text.ENGLISH_STOP_WORDS.union(custom_stop_words) count_vect = CountVectorizer(stop_words=mssqltips_stop_words) count_matrix = count_vect.fit_transform([clean_text]) word_list = count_vect.get_feature_names_out() count_list = count_matrix.toarray() word_frequency_dict = dict(zip(word_list, count_list[0])) # sort dictionary by values rtn_value = {k: v for k, v in sorted(word_frequency_dict.items(), key=lambda item: item[1], reverse=True)} return rtn_value word_frequency_dict = count_word_frequencies(clean_text_data(content)) dict_items = word_frequency_dict.items() first_ten_words = list(dict_items)[:10] print(first_ten_words) # Output #[('edgewood', 6), ('solutions', 6), ('content', 3), ('copyright', 3), ('rights', 3), ('written', 3), ('copyrights', 2), ('express', 2), ('form', 2), ('intellectual', 2)]
The above script uses the variable “content,” defined in Section 1.4, that contains the extracted text on the “Copyright” page. The output presents the top 10 most frequently used words on the page. The output may still have some meaningless words. Note that we execute some common cleaning steps. Text data cleaning is an iterative process. We usually start simple and then iterate (Imasogie, 2019).
7 – Visualizing Text Data Using a Word Cloud
We can visualize the word frequencies using a word cloud (also known as a tag cloud). The word cloud, a visual representation of text data, can use font size and color to show the relative importance of words in a text. For example, if a word has a large font size, the word shows up more often in the text. Correspondingly, the word is more important in the context (Klein, 2021). To demonstrate the word cloud technique, we generate a word cloud for the "Copyright" page using the following script. The word cloud should look like Figure 1.
import matplotlib.pyplot as plt from wordcloud import WordCloud from sklearn.feature_extraction import text custom_stop_words = ['site','web','llc','does','wwwmssqltipscom'] # Combine the custom stop words into the built-in stop words mssqltips_stop_words = text.ENGLISH_STOP_WORDS.union(custom_stop_words) word_cloud = WordCloud(width=400, height=300, margin=0, stopwords=mssqltips_stop_words, background_color="white", colormap="Dark2", max_font_size=50, random_state=30) word_cloud.generate(clean_text_data(content)) plt.figure() plt.imshow(word_cloud, interpolation="bilinear") plt.axis("off") plt.show()
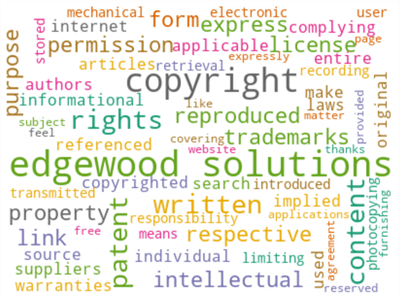
Figure 1 Word Frequencies on the Copyright Page
8 – The Complete Source Code
This content audit project asks us to gather a list of information about a web page. According to the project requirement, the list contains these fields: Page Id, Page Title, Document Type, URL, High-frequency words, Meta Description, Internal Links, External Links, and Broken Links. So, we write a Python program to implement the project requirements and extract text data from the Copyright page on MSSQLTips. By and large, the program includes these eleven steps:
- Initializes variables, where we give the page URL and the Excel file name
- Requests the URL and reads the web page content.
- Uses the web content to construct a Beautiful Soup object, representing the document as a nested data structure.
- Uses a simple way to navigate that data structure and find the page title.
- Uses a regular expression to extract the sub-directory from the page URL. The subdirectory represents the document type.
- Uses Beautiful Soup "find(tagName, tagAttributes)" method to locate the meta description.
- Uses scikit-learn's CountVectorizer to count word frequencies and takes top 10 high-frequency words from a Python dictionary.
- Uses a regular expression and Beautiful Soup to extract internal links.
- Uses a regular expression and Beautiful Soup to extract external links.
- Extracts all links on the web page and uses the Python "requests" library to find broken links.
- Saves audit data to an Excel file using the Python "xlwt" library.
Click here for the complete code. After executing the program, the Excel file should look like Figure 2.

Figure 2 The Web Page Audit Report
Summary
We scratched the surface of content strategy for the web. Web content should support key business objectives or fulfill users' needs. On the other hand, irrelevant content dissatisfies users, and can even provide misleading information. Before deciding about content strategy, we need to know what we have already on the website. Therefore, we should do a content audit. This article introduced several advanced web scraping techniques and used these techniques to perform a web page audit.
We started with a gentle introduction to web content audit. We then proposed a list of fields that we should gather from the web page. Next, we explored how Beautiful Soap worked with lambda expressions, regular expressions, Christian Kohlschütter's library, and scikit-learn's CountVectorizer.
We also practiced a typical text data cleaning process and visualized text data using a word cloud.
Finally, the article provided the complete source code that covers all steps to collect audit data from a web page and save it to an Excel spreadsheet.
Reference
Broucke, V. S. & Baesens, B. (2018). Practical Web Scraping for Data Science: Best Practices and Examples with Python. New York, NY: Apress.
Chi, C. (2021). The 5 Basic Parts of a URL: A Short Guide. https://blog.hubspot.com/marketing/parts-url/.
Gupta, R. (2019). Cleaning Web-Scraped Data With Pandas and Regex! (Part I). https://towardsdatascience.com/cleaning-web-scraped-data-with-pandas-and-regex-part-i-a82a177af11b.
Halvorson, K. & Rach, M. (2012). Content Strategy for the Web, Second Edition. Berkeley, CA: New Riders.
Imasogie, N. (2019). Stand-Up Comedy and NLP. https://medium.com/nwamaka-imasogie/stand-up-comedy-and-nlp-c7d64002520c.
Klein, B. (2021). Python Wordcloud Tutorial. https://python-course.eu/applications-python/python-wordcloud-tutorial.php.
Kohlschütter, C. (2016). Boilerpipe. http://boilerpipe-web.appspot.com/.
Kohlschütter, C., Fankhauser, P. & Nejdl, W. (2010). Boilerplate detection using shallow text features. WSDM '10: Proceedings of the third ACM international conference on Web search and data mining (Pages 441–450). https://doi.org/10.1145/1718487.1718542.
Jain, P. (2021). Basics of CountVectorizer. https://towardsdatascience.com/basics-of-countvectorizer-e26677900f9c.
Jankovic, D. (2020). How to Conduct a Website Content Analysis to Discover Insights & Opportunities. https://divvyhq.com/tips-how-tos/how-to-conduct-website-content-analysis/.
Mitchell, R. (2018). Web Scraping with Python, 2nd Edition. Sebastopol, CA: O'Reilly Media.
Redsicker, P. (2012). Content Quality: A Practical Approach to Content Analysis. https://contentmarketinginstitute.com/2012/02/content-quality-practical-approach-to-content-analysis/.
Riebold, J. (2021). boilerpy3 1.0.5. https://pypi.org/project/boilerpy3/.
Summet, J. (2014). Data Manipulation for Science and Industry. https://www.summet.com/dmsi/html/index.html.
Next Steps
- We explored some web scraping techniques in this article. We often see the term "web crawling" when learning data gathering. The difference between "web scraping" and "web crawling" is relatively vague, as many authors and programmers use both terms interchangeably (Broucke & Baesens, 2018). However, they have different concerns, and we should separate them into different units when programming. For example, we usually use the web crawling technique to traverse web pages and extract URLs. By contrast, we use the web scraping technique to extract information on every individual web page. Therefore, we should know some web crawling techniques to conduct a website content analysis. We may adopt either a depth-first search (DFS) algorithm or a breadth-first search (BFS) algorithm to crawl a website. When using breadth-first crawling, we crawl every URL at the current depth before proceeding to the next level. On the other hand, the depth-first crawling algorithm travels as far as possible down one branch before backtracking.
- Check out these related tips:
- CRUD Operations in SQL Server using Python
- CRUD Operations on a SharePoint List using Python
- Learning Python in Visual Studio 2019
- Python Programming Tutorial with Top-Down Approach
- Recursive Programming Techniques using Python
- Using Python to Download Data from an HTML Table to an SQL Server Database

Nai Biao Zhou has twenty years of experience in software development, with strong analytical skills and a broad range of computer expertise.
He has fifteen years of experience in development and maintenance of database applications on SQL Server in OLTP/OLAP/BI environments.
He has a master’s degree in Control Engineering and is pursuing a Master of Science degree in Predictive Analytics.
Knowledge/Skills
Advanced computer programming skills and well versed with C/C#, Java, ASP.NET, JavaScript, and SQL.
In depth knowledge of Solution Architecture, and Software Development Life Cycle (SDLC).
Microsoft Certified Application Developer (MCAD) since 2004.
- MSSQLTips Awards: Author of the Year – 2021 | Rising Star (50+ tips) – 2024 | Author Contender – 2020, 2023


